Exploration de sites Web (Website crawling) : quoi, pourquoi et comment optimiser
Vous ne savez pas par où commencer pour vous assurer que vos pages sont explorées ? Du lien interne à l’instruction de Googlebot, voici ce qu’il faut prioriser.

Le crawling est essentiel pour tous les sites Web, grands et petits.
Si votre contenu n’est pas exploré, vous n’avez aucune chance de gagner en visibilité sur les surfaces Google.
Parlons de la façon d’ optimiser l’exploration pour donner à votre contenu l’exposition qu’il mérite.
Qu’est-ce que le crawling dans le référencement SEO
Dans le contexte du référencement SEO, l’exploration est le processus par lequel les robots des moteurs de recherche (également appelés robots d’indexation, web crawlers ou spiders) découvrent systématiquement le contenu d’un site Web.
Il peut s’agir de texte, d’images, de vidéos ou d’autres types de fichiers accessibles aux robots. Quel que soit le format, le contenu se trouve exclusivement via des liens.
Comment fonctionne le web crawling
Un robot d’exploration Web fonctionne en découvrant les URL et en téléchargeant le contenu de la page.
Au cours de ce processus, ils peuvent transmettre le contenu à l’index du moteur de recherche et extraire des liens vers d’autres pages Web.
Ces liens trouvés entreront dans différentes catégories :
- Nouvelles URL inconnues du moteur de recherche.
- Les URL connues qui ne donnent aucune indication sur l’exploration seront périodiquement revisitées pour déterminer si des modifications ont été apportées au contenu de la page, et donc l’index du moteur de recherche doit être mis à jour.
- URL connues qui ont été mises à jour et donnent des indications claires. Ils doivent être réexplorés et réindexés, par exemple via un horodatage de la date du dernier mod du sitemap XML.
- URL connues qui n’ont pas été mises à jour et donnent des indications claires. Ils ne doivent pas être réexplorés ou réindexés, comme un header de réponse HTTP 304 Not Modified.
- URL inaccessibles qui ne peuvent ou ne doivent pas être suivies, par exemple celles derrière un formulaire de connexion ou des liens bloqués par une balise robots « nofollow ».
- URL non autorisées que les robots des moteurs de recherche n’exploreront pas, par exemple, celles bloquées par le fichier robots.txt.
Toutes les URL autorisées seront ajoutées à une liste de pages à visiter ultérieurement, connue sous le nom de file d’attente d’exploration (crawl queue) .
Cependant, ils se verront attribuer différents niveaux de priorité.
Cela dépend non seulement de la catégorisation des liens, mais d’une foule d’autres facteurs qui déterminent l’importance relative de chaque page aux yeux de chaque moteur de recherche.
Les moteurs de recherche les plus populaires ont leurs propres bots qui utilisent des algorithmes spécifiques pour déterminer ce qu’ils explorent et quand. Cela signifie que tous ne crawlent pas de la même manière.
Googlebot se comporte différemment de Bingbot, DuckDuckBot, Yandex Bot ou Yahoo Slurp.
Pourquoi il est important que votre site puisse être exploré
Si une page d’un site n’est pas explorée, elle ne sera pas classée dans les résultats de recherche, car il est très peu probable qu’elle soit indexée.
Mais les raisons pour lesquelles l’exploration est essentielle vont beaucoup plus loin.
Une exploration rapide est essentielle pour un contenu limité dans le temps.
Souvent, s’il n’est pas exploré et s’il n’est pas visible rapidement, il devient inutile pour les utilisateurs.
Par exemple, le public ne sera pas intéressé par les dernières nouvelles de la semaine dernière, un événement qui est passé ou un produit qui est maintenant épuisé.
Mais même si vous ne travaillez pas dans un secteur où le délai de mise sur le marché est critique, une exploration rapide est toujours bénéfique.
Lorsque vous actualisez un article ou publiez une modification significative du référencement sur la page, plus Googlebot l’explore rapidement, plus vite vous bénéficierez de l’optimisation – ou vous verrez votre erreur et pourrez revenir en arrière.
Vous ne pouvez pas échouer rapidement si Googlebot explore lentement.
Considérez le crawling comme la pierre angulaire du référencement ; votre visibilité organique dépend entièrement du fait qu’elle soit bien faite sur votre site Web.
Mesurer le crawl : budget de crawl vs. Efficacité de l’exploration
Contrairement à l’opinion populaire, Google n’a pas pour objectif d’ explorer et d’indexer tout le contenu de tous les sites Web sur Internet.
Le crawl d’une page n’est pas garanti. En fait, la plupart des sites ont une partie importante de pages qui n’ont jamais été explorées par Googlebot.
Si vous voyez l’exclusion « Découvert – actuellement non indexé » (« Discovered – currently not indexed”) dans le rapport d’indexation des pages de la console de recherche Google, ce problème vous concerne.
Mais si vous ne voyez pas cette exclusion, cela ne signifie pas nécessairement que vous n’avez aucun problème d’exploration.
Il existe une idée fausse commune sur les métriques significatives lors de la mesure de l’exploration.
Erreur de budget de crawl
Les professionnels du référencement se tournent souvent vers le budget d’exploration , qui fait référence au nombre d’URL que Googlebot peut et veut explorer dans un laps de temps spécifique pour un site Web particulier.
Ce concept pousse à la maximisation de l’exploration. Ceci est encore renforcé par le rapport d’état d’exploration de Google Search Console indiquant le nombre total de demandes d’exploration.
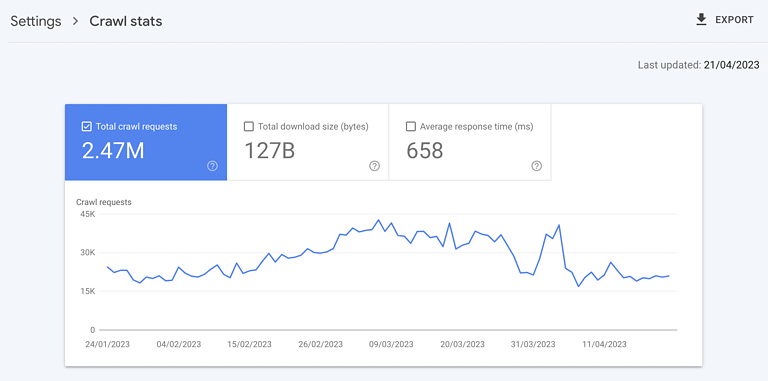
Capture d’écran de Google Search Console, mai 2023
{kind=link}
Mais l’idée que plus crawling est intrinsèquement meilleur est complètement erronée. Le nombre total de crawls n’est rien d’autre qu’une métrique de vanité.
Attirer 10 fois le nombre de crawls par jour n’est pas nécessairement corrélé à une (ré)indexation plus rapide du contenu qui vous intéresse. Tout cela est en corrélation avec le fait de mettre plus de charge sur vos serveurs, ce qui vous coûte plus cher.
L’accent ne doit jamais être mis sur l’augmentation du nombre total d’explorations, mais plutôt sur une exploration de qualité qui se traduit par une valeur SEO.
Valeur d’efficacité du crawl
Une exploration de qualité signifie réduire le temps entre la publication ou la mise à jour importante d’une page pertinente pour le référencement et la prochaine visite de Googlebot. Ce délai est l’ efficacité du crawl .
Pour déterminer l’efficacité de l’exploration, l’approche recommandée consiste à extraire la valeur datetime créée ou mise à jour de la base de données et à la comparer à l’horodatage de la prochaine exploration Googlebot de l’URL dans les fichiers journaux du serveur.
Si cela n’est pas possible, vous pouvez envisager de la calculer à l’aide de la date de dernière modification dans les sitemaps XML et d’interroger périodiquement les URL pertinentes avec l’API d’inspection d’URL de la Search Console jusqu’à ce qu’elle renvoie un état de dernière analyse.
En quantifiant le délai entre la publication et le crawl, vous pouvez mesurer l’impact réel des optimisations de crawl avec une métrique qui compte.
Au fur et à mesure que l’efficacité de l’exploration diminue, le contenu pertinent pour le référencement nouveau ou mis à jour plus rapidement sera présenté à votre public sur les surfaces Google.
Si le score d’efficacité de l’exploration de votre site indique que Googlebot met trop de temps à visiter un contenu important, que pouvez-vous faire pour optimiser l’exploration ?
Prise en charge du moteur de recherche pour l’exploration
On a beaucoup parlé ces dernières années de la façon dont les moteurs de recherche et leurs partenaires se concentrent sur l’amélioration de l’exploration.
Après tout, c’est dans leur meilleur intérêt. Une exploration plus efficace leur donne non seulement accès à un meilleur contenu pour optimiser leurs résultats, mais aide également l’écosystème mondial en réduisant les gaz à effet de serre.
La plupart des discussions ont porté sur deux API visant à optimiser l’exploration.
L’idée est plutôt que les robots des moteurs de recherche ne décident quoi explorer, les sites Web peuvent pousser les URL pertinentes directement vers les moteurs de recherche via l’API pour déclencher une analyse.
En théorie, cela vous permet non seulement d’indexer plus rapidement votre dernier contenu, mais offre également un moyen de supprimer efficacement les anciennes URL, ce qui n’est actuellement pas bien pris en charge par les moteurs de recherche.
Assistance non Google d’IndexNow
La première API est IndexNow . Ceci est pris en charge par Bing, Yandex et Seznam, mais surtout pas Google. Il est également intégré à de nombreux outils SEO, CRM et CDN, réduisant potentiellement l’effort de développement nécessaire pour tirer parti d’IndexNow.
Cela peut sembler être une victoire rapide pour le référencement, mais soyez prudent.
Une partie importante de votre public cible utilise-t-elle les moteurs de recherche pris en charge par IndexNow ? Sinon, déclencher des crawls depuis leurs bots peut avoir une valeur limitée.
Mais plus important encore, évaluez ce que l’intégration sur IndexNow fait pour le poids du serveur par rapport à l’amélioration du score d’efficacité de l’exploration pour ces moteurs de recherche. Il se peut que les coûts ne valent pas les avantages.
Assistance Google à partir de l’API d’indexation
Le second est l’ API d’indexation Google . Google a déclaré à plusieurs reprises que l’API ne peut être utilisée que pour explorer des pages avec des offres d’emploi ou des balisages d’événements de diffusion. Et beaucoup ont testé cela et prouvé que cette affirmation était fausse.
En soumettant des URL non conformes à l’API d’indexation Google, vous constaterez une augmentation significative de l’exploration. Mais c’est le cas parfait pour expliquer pourquoi « l’optimisation du budget de crawl » et baser les décisions sur la quantité de crawl est mal conçue.
Car pour les URL non conformes, la soumission n’a aucun impact sur l’indexation. Et quand on s’arrête pour y penser, cela prend tout son sens.
Vous ne soumettez qu’une URL. Google explorera rapidement la page pour voir si elle contient les données structurées spécifiées.
Si c’est le cas, cela accélérera l’indexation. Sinon, ce ne sera pas le cas. Google l’ignorera.
Ainsi, appeler l’API pour des pages non conformes ne fait rien d’autre qu’ajouter une charge inutile sur votre serveur et gaspiller des ressources de développement sans gain.
Assistance Google dans la console de recherche Google
L’autre manière dont Google prend en charge l’exploration est la soumission manuelle dans Google Search Console .
La plupart des URL soumises de cette manière seront explorées et verront leur statut d’indexation modifié dans l’heure qui suit. Mais il y a une limite de quota de 10 URL dans les 24 heures, donc le problème évident avec cette tactique est l’échelle.
Cependant, cela ne signifie pas l’ignorer.
Vous pouvez automatiser la soumission des URL que vous considérez comme une priorité via des scripts qui imitent les actions de l’utilisateur pour accélérer l’exploration et l’indexation pour les quelques privilégiés.
Enfin, pour quiconque espère cliquer sur le bouton « Valider le correctif » sur les exclusions « découvert actuellement non indexé », cela déclenchera l’exploration, dans mes tests à ce jour, cela n’a rien fait pour accélérer l’exploration.
Donc, si les moteurs de recherche ne nous aident pas de manière significative, comment pouvons-nous nous aider nous-mêmes ?
Comment réaliser une exploration efficace du site
Il existe cinq tactiques qui peuvent faire la différence pour l’efficacité du crawl.
1. Assurez une réponse rapide et saine du serveur
Capture d’écran de Google Search Console, mai 2023
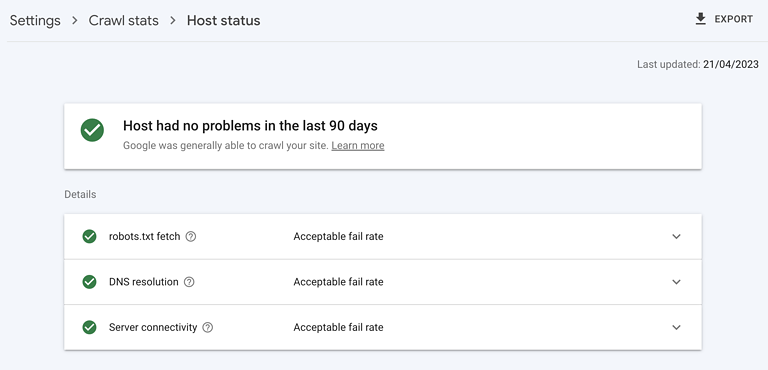{kind=link}
Un serveur hautement performant est essentiel. Il doit être capable de gérer la quantité d’exploration que Googlebot souhaite effectuer sans aucun impact négatif sur le temps de réponse du serveur ou sans erreur.
Vérifiez que le statut de l’hébergeur de votre site est vert dans Google Search Console, que les erreurs 5xx sont inférieures à 1 % et que la tendance des temps de réponse du serveur est inférieure à 300 millisecondes.
2. Supprimer le contenu sans valeur
Lorsqu’une partie importante du contenu d’un site Web est de mauvaise qualité, obsolète ou dupliquée, elle détourne les robots d’exploration de la visite de contenu nouveau ou récemment mis à jour et contribue au gonflement de l’ index .
Le moyen le plus rapide de commencer à nettoyer est de vérifier le rapport des pages de la console de recherche Google pour l’exclusion « Exploré – actuellement non indexé ».
Dans l’exemple fourni, recherchez des modèles de dossier ou d’autres signaux de problème. Pour ceux que vous trouvez, corrigez-le en fusionnant un contenu similaire avec une redirection 301 ou en supprimant le contenu avec une redirection 404, selon le cas.
3. Indiquez à Googlebot ce qu’il ne faut pas explorer
Bien que les liens rel=canonical et les balises noindex soient efficaces pour garder l’index Google de votre site Web propre, ils vous coûtent cher en exploration.
Bien que cela soit parfois nécessaire, demandez-vous si ces pages doivent être explorées en premier lieu. Si ce n’est pas le cas, arrêtez Google au stade de l’exploration avec un refus de robot.txt.
Trouvez des cas où il peut être préférable de bloquer le robot plutôt que de donner des instructions d’indexation en consultant le rapport de couverture de Google Search Console pour les exclusions des balises canoniques ou noindex.
Examinez également l’exemple d’URL « Indexée, non soumise dans le plan du site » et « Découverte – actuellement non indexée » dans Google Search Console. Trouvez et bloquez les itinéraires pertinents non SEO tels que :
- Pages de paramètres , telles que ?sort=oldest.
- Pages fonctionnelles, telles que « panier ».
- Espaces infinis, comme ceux créés par les pages de calendrier.
- Images, scripts ou fichiers de style sans importance.
- URL des API.
Vous devez également tenir compte de l’impact de votre stratégie de pagination sur l’exploration.
4. Indiquez à Googlebot quoi explorer et quand
Un sitemap XML optimisé est un outil efficace pour guider Googlebot vers des URL pertinentes pour le référencement.
Optimisé signifie qu’il se met à jour dynamiquement avec un délai minimal et inclut la date et l’heure de la dernière modification pour informer les moteurs de recherche lorsque la dernière page a été modifiée de manière significative et si elle doit être reexplorée.
5. Prise en charge de l’exploration via des liens internes
Nous savons que l’exploration ne peut se produire que via des liens. Les plans de site XML sont un excellent point de départ ; les liens externes sont puissants mais difficiles à construire en masse avec qualité.
Les liens internes, en revanche, sont relativement faciles à mettre à l’échelle et ont des impacts positifs significatifs sur l’efficacité du crawl.
Portez une attention particulière à la navigation sur l’ensemble du site mobile, au fil d’Ariane, aux filtres rapides et aux liens de contenu associés, en vous assurant qu’aucun ne dépend de Javascript.
Optimiser l’exploration Web
J’espère que vous êtes d’accord : l’exploration de sites Web est fondamentale pour le référencement.
Et maintenant, vous disposez d’un véritable KPI en termes d’efficacité du crawl pour mesurer les optimisations, ce qui vous permet de faire passer vos performances organiques au niveau supérieur.